What is going on with WirePlumber?
I’ve been quiet about WirePlumber for a significant amount of time. It was back in 2022 when after a series of issues were found in its design, I made the call to rework some of its fundamentals in order to allow it to grow. I mentioned this in the Collabora blog at the time. And long story short, the year now is 2024 (time flies, who knew?!).
What were the issues?
The main limiting factor in the design was the within the most powerful feature of WirePlumber: the scripting system. When we designed the scripting system, the hypothesis was that if we provided an API that would allow scripts to get references to PipeWire objects and subscribe to their events independently, then any functionality could easily be built on top. This couldn’t have been more wrong, because, as it turned out, components built on top of scripts actually depend on one another and it is critical at times to be able to ensure the order in which the event handlers (callbacks) will be executed. Furthermore, what we also realised was that it was hard to write relatively small scripts. Big chunks of logic quickly started accumulating within single script files, making them quite hard to work with. This also made it impossible for users to slightly modify certain behaviour without having to copy the entire script first.
The solution was to redo the scripting system in a different way. Instead of letting the scripts do whatever they want, we introduced a central component that manages references to all the PipeWire objects, the “standard event source”. And in addition, we added a mechanism for scripts to subscribe to events from those objects using other objects that we call “hooks”. The hooks can have dependencies between one another, allowing them to be ordered, and they can pass data between them, allowing them to co-operate on making decisions instead of racing against one another.
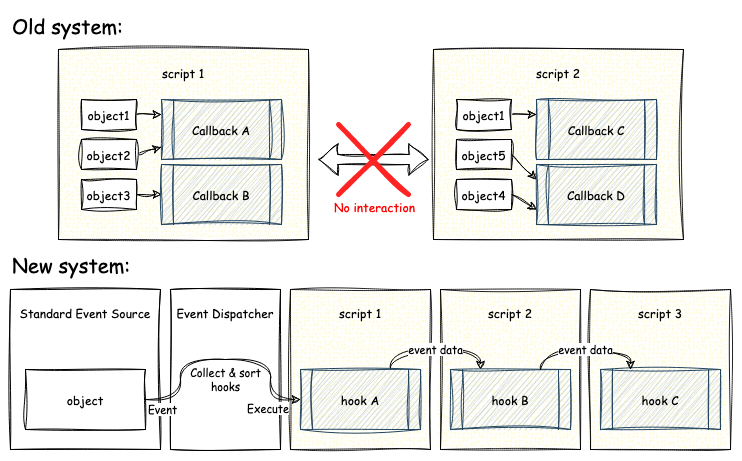
This was a game changer. After working with this system for a while and transforming the old scripts to use hooks, it all became much cleaner and easy to work with.
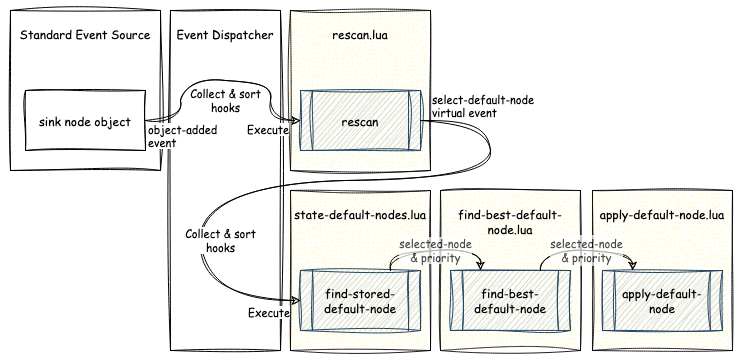
Along this process, we also realised that we could introduce virtual events, that do not originate from PipeWire objects, in order to run chains of hooks to make decisions. For instance, the process of selecting which “sink” node is going to be the default audio output of the system has been implemented with a virtual event called “select-default-node”. This event is generated within a hook that reacts to several events which can be interpreted as potential changes in the sinks. When the event is generated, a list of available sink nodes with their properties is collected and passed onto the “select-default-node” hooks as event data. Afterwards, each hook runs through this list and attempts to make a decision based on some heuristics. If the hook makes a decision, it stores the selected node together with a priority number in the event data. Then the next hook in the chain starts from there and makes its own decision, but it only changes the result if the priority ends up being higher than the previous one.
As you can tell, this system makes it easy for users to override the default logic with minimal effort. In the above example of hooks that select the default “sink”, for instance, a user could add a custom script with a hook that also reacts to the “select-default-node” event and is linked in a specific position in the existing hooks chain, using hook dependencies. That hook can then introduce custom logic for selecting the default sink and store it with a much higher priority, to override the decisions made by the other hooks. The interesting part here is that it does not need to always store a result; it is perfectly fine to return without taking any action and let the existing upstream hooks make a decision themselves, allowing the custom hook to be as minimal as possible in its logic.
Where are we now?
For about 2 years now, this entire refactoring work used to live in a branch called “next”. In the beginning of January this year, I merged this into “master” and made a first pre-release of what will become WirePlumber 0.5.0. Then last week, I made a second pre-release (version 0.4.82).
Apart from the scripting system changes, there also several other features that
have accumulated during this time. We have made changes in the
configuration
system, utilising
SPA-JSON
files, a dependency-based system for loading
components
and dynamic settings
accessible via wpctl. We have also introduced
“smart filters”,
a system to automatically plug filter nodes in front of device
nodes, and based on that we have also
refactored the Bluetooth auto-switch
mechanism to always provide a virtual Bluetooth source that auto-switches the
underlying headset device to the HSP/HFP profile when this source is linked to
an application. And all that is further enhanced by refinements in the linking
policy, which now supports further fine-tuning through
new node properties,
and a built-in
deduplication mechanism for camera devices,
allowing the libcamera and V4L2 monitors to run in parallel but with only one of
them providing a node for each camera, depending on the camera type.
This week I am working on some more configuration system improvements and the plan is to get a release candidate out by next week. This should pave the path for a final release soon afterwards, provided that no serious issues are found. Of course, your feedback is going to be invaluable to make this go smoothly, so stay tuned!
What’s next?
With the right infrastructure in place, I believe that WirePlumber is very well positioned now more than ever to grow. To start with, after all this time, there are still features missing that would make a lot of sense to have.
One such feature, for instance, is the ability to follow JACK-like rules for linking arbitrary ports together. So far, WirePlumber’s linking policy operates on nodes and takes action on linking together nodes, instead of ports. Then there is a component that automatically discovers the ports of those nodes and links them together one by one. Because the existing policy operates on nodes, such a feature would easily conflict, but with the new hooks system I am confident they can be made to work together.
Another big missing feature is proper access control. Our access control scripts have not even been ported to the hooks system, so that is a first action to take. But more importantly, WirePlumber in my opinion needs to have a mechanism to maintain groups of objects and groups of clients and make sure that the permission bits for those objects are kept up-to-date for each client every time there is a change in the registry. Grouping would allow us to build access control rules, similar to how user groups work on the file system.
Beyond missing features, I would love to see proper “mixer controls” and “default nodes” APIs becoming part of the WirePlumber library. Currently, we have this functionality built as modules that provide some objects that can be interacted with using GObject signals and properties. This was done to avoid committing to public APIs and it’s fine for Lua scripts, but it has limitations and awkwardness. Most importantly, though, these APIs fail to work well with the “standard event source” and the hooks system, because they maintain their own references to PipeWire objects and fall into the same trap that the scripts used to. This needs a little bit of redesign, to make sure that external references can be used without compromising the ability to use these APIs in client applications, outside the WirePlumber daemon.
Apart from all these, I would be very interested to see 3rd-party applications taking advantage of the features that we have built in. It would make sense, for example, for a filtering application to use the “smart filters” functionality, or provide 3rd-party hooks to extend the linking policy. I am sure that as these features are getting utilised and improved, the user experience can be improved significantly.
